
Introduction to Hash Table Data Structure
In the vast landscape of data structures, one fundamental tool stands out for its efficiency in data retrieval and storage: the Hash Table. This article serves as a comprehensive guide to understanding Hash Tables, exploring its significance in programming, characteristics, types, advantages, disadvantages, and providing code snippets in various programming languages to illustrate its implementation.

What is a Hash Tables Data Structure
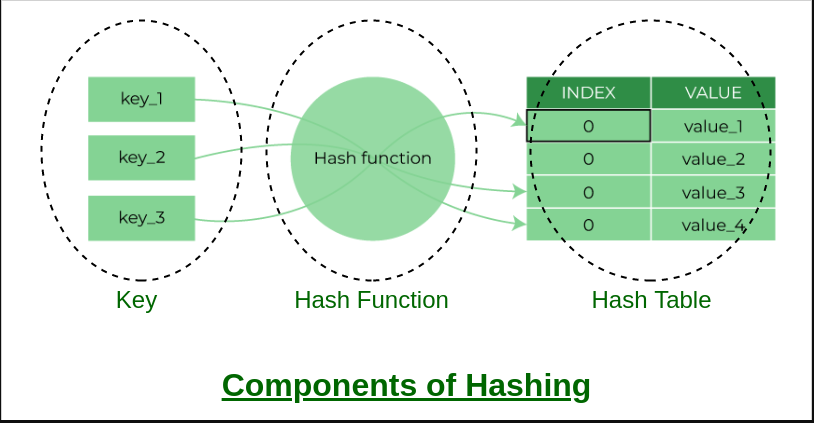
A Hash Table is a data structure that stores key-value pairs and uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be retrieved or inserted with optimal time complexity. This mechanism enables fast retrieval of data, making Hash Tables an indispensable tool in programming.
Why We Use Hash Tables Data Structure in Programming
Hash Tables offer exceptional performance in scenarios requiring quick access to data. They are widely used in programming for tasks such as implementing associative arrays, symbol tables, database indexing, and caching mechanisms. With constant time complexity for basic operations like insertion, deletion, and retrieval (on average), Hash Tables ensure efficient data management in diverse applications.
Characteristics of Hash Tables Data Structure
- Efficient data retrieval using hash functions
- Constant time complexity for basic operations (average case)
- Dynamic resizing to maintain performance under varying loads
- Collision resolution mechanisms to handle hash collisions
Types of Hash Tables Data Structure
- Separate Chaining: Utilizes linked lists to handle collisions by storing multiple elements in the same bucket.
- Open Addressing: Employs probing techniques to find an alternative empty slot upon encountering a collision, ensuring all elements are stored within the table itself.
Advantages of Hash Tables Data Structure
- Rapid data retrieval with constant time complexity (average case)
- Flexible storage of key-value pairs, suitable for various applications
- Efficient memory utilization through dynamic resizing
- Versatile collision resolution mechanisms to maintain performance
Disadvantages of Hash Tables Data Structure
- Performance degradation under high collision rates
- Complexity in designing effective hash functions
- Additional memory overhead due to dynamic resizing and collision resolution mechanisms
Code Snippets of Hash tables Data Structure
Hash tables in C#
using System;
using System.Collections;
class Program
{
static void Main(string[] args)
{
Hashtable hashtable = new Hashtable();
hashtable.Add("key1", "value1");
hashtable.Add("key2", "value2");
hashtable.Add("key3", "value3");
Console.WriteLine(hashtable["key2"]);
}
}
Output
value2
Hash tables in C
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define TABLE_SIZE 10
typedef struct Node {
char* key;
char* value;
struct Node* next;
} Node;
Node* hashTable[TABLE_SIZE] = {NULL};
int hashFunction(char* key) {
int hash = 0;
for (int i = 0; i < strlen(key); i++) {
hash += key[i];
}
return hash % TABLE_SIZE;
}
void insert(char* key, char* value) {
int index = hashFunction(key);
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->key = key;
newNode->value = value;
newNode->next = NULL;
if (hashTable[index] == NULL) {
hashTable[index] = newNode;
} else {
Node* current = hashTable[index];
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}
}
char* search(char* key) {
int index = hashFunction(key);
Node* current = hashTable[index];
while (current != NULL) {
if (strcmp(current->key, key) == 0) {
return current->value;
}
current = current->next;
}
return NULL;
}
int main() {
insert("key1", "value1");
insert("key2", "value2");
insert("key3", "value3");
printf("%s\n", search("key2"));
return 0;
}
Output
value2
Hash tables in C++
#include <iostream>
#include <unordered_map>
int main() {
std::unordered_map<std::string, std::string> hashtable;
hashtable["key1"] = "value1";
hashtable["key2"] = "value2";
hashtable["key3"] = "value3";
std::cout << hashtable["key2"] << std::endl;
return 0;
}
Output
value2
Hash tables in Python
hash_table = {}
hash_table["key1"] = "value1"
hash_table["key2"] = "value2"
hash_table["key3"] = "value3"
print(hash_table["key2"])
Output
value2
Hash tables in PHP
<?php $hashTable = array(); $hashTable["key1"] = "value1"; $hashTable["key2"] = "value2"; $hashTable["key3"] = "value3"; echo $hashTable["key2"]; ?>
Output
value2
Hash tables in JAVA
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
HashMap<String, String> hashtable = new HashMap<>();
hashtable.put("key1", "value1");
hashtable.put("key2", "value2");
hashtable.put("key3", "value3");
System.out.println(hashtable.get("key2"));
}
}
Output
value2
Hash tables in JavaScript
let hashtable = {};
hashtable["key1"] = "value1";
hashtable["key2"] = "value2";
hashtable["key3"] = "value3";
console.log(hashtable["key2"]);
Output
value2
Conclusion
In conclusion, Hash Tables emerge as a cornerstone data structure in programming, facilitating efficient storage and retrieval of key-value pairs. Their characteristics, types, advantages, and disadvantages underscore their significance in various applications, ranging from database indexing to symbol tables. By leveraging Hash Tables and understanding their implementation across multiple programming languages, developers can optimize data management and enhance the performance of their applications.
For more visit my website Codelikechamp.com



